Stat 7770, Module 06
February 2023
Setting a theme
- Seaborn comes with themes that provide an overall aesthetic for the plots.
- We will start by using the default, then change it later.
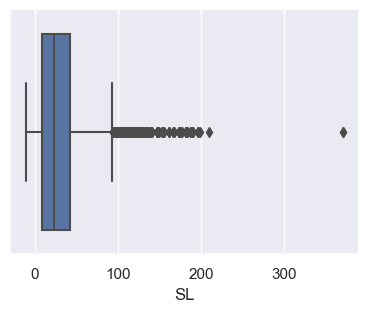
- Note that the boxplot easily identifies the gross outlier(s) and shows the skewness of the distribution.
sns.set() # The default theme.
sns.set(rc={'figure.figsize':(4.5,3.18)}) # A default plot size for axes level plots.
op_data['SL'] = op_data['ScheduleLag'].dt.days # Create a new variable that has schedule lag in days.
sns.boxplot(x='SL', data=op_data); # Create a default boxplot. The semi-colon is a trick to stop unwanted output on the terminal.
pass # Another way to surpress unwanted text output from the plot commands.
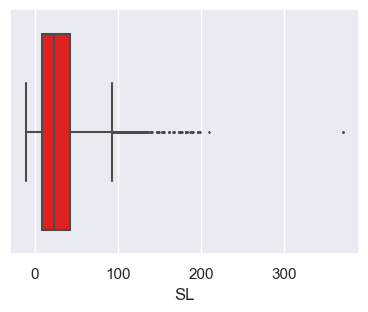
Changing some of the boxplot parameters
- Below we change the boxplot color and the size of the data points.
# Note below that the data argument is not quoted, but the x argument is quoted.
# "Flier" is the name for the outliers.
sns.boxplot(x='SL', data = op_data, color='red', fliersize=1.0);
pass
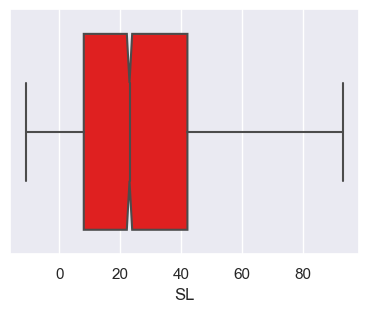
The tweaked boxplot
g = sns.boxplot(x='SL', data = op_data, color='red', fliersize=1.0, notch=True, sym="");
print(type(g))<class 'matplotlib.axes._subplots.AxesSubplot'>
Using the catplot command
- You can also make the box plot, from the high-level (figure-level) plotting function, ‘catplot’.
- The plot size can be controlled with the height and aspect arguments.
g = sns.catplot(x='SL', data = op_data, kind="box", height = 2, aspect=2) # A boxplot, from the "catplot" figure level command.
g.set_xlabels("Schedule lag") # You can tweak these plots using built in methods.
g.fig.suptitle('Distribution of schedule lags')
print(type(g));<class 'seaborn.axisgrid.FacetGrid'>
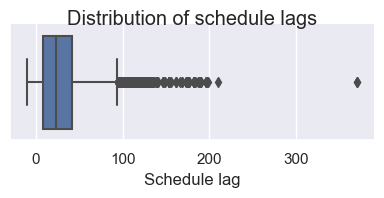
Changing the ‘kind’ argument
- A violin plot shows the distribution of a variable, in a way that makes it easier to compare distributions across levels of a categorical variable. For now, we will do a single plot.
- All we have to do here is switch out the ‘kind=“box”’ to ‘kind=“violin”’:
g = sns.catplot(x='SL', data = op_data, kind="violin",height=4) # A boxplot, from the "catplot" figure level command.
g.set_xlabels("Schedule lag") # You can tweak these plots using built in methods.
g.fig.suptitle('Distribution of schedule lags');
pass
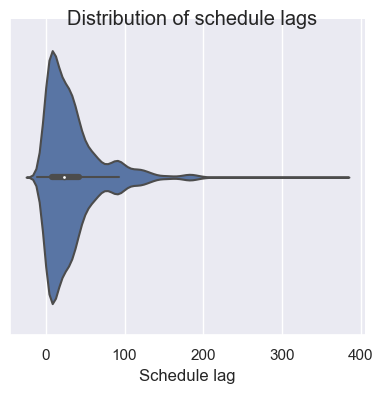
Histograms and distributions
- The figure-level command for a histogram is displot(), which by default will create a histogram of a numeric variable.
- It can also add a kernel density estimate (KDE) of the distribution. Basically, the KDE smooths the tops of the bins.
sns.displot(op_data['SL'], kde=True, height=4,aspect=2);
pass
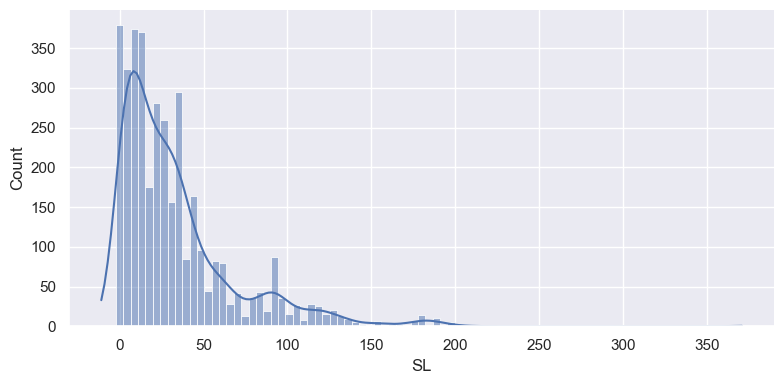
Fine tuning the plot
- Below we remove the KDE and add a “rug plot”, that marks the individual observations.
sns.displot(op_data['SL'], kde=False, rug=True,height=4, aspect=2); # Remove the kernel density estimate and add a rug plot.
pass
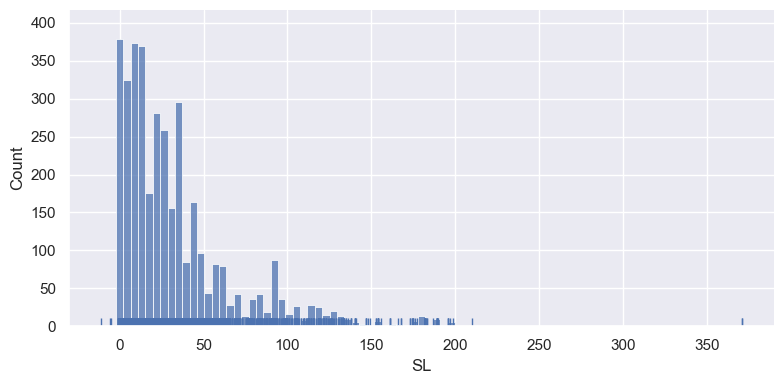
Saving a plot to a file
- There are various graphic file formats available, such as .png, .jpeg, .svg.
- You simply have to include the file extension in the name to choose between formats.
import os
os.chdir('C:\\Users\\water\\Dropbox (Penn)\\Teaching\\7770s2023\\Images')
sns.displot(op_data['SL'], kde=True, height=4, aspect=2);
plt.savefig("output_{0}.png".format('OP')) # savefig method for png format.
plt.savefig("output_{0}.jpeg".format('OP')) # savefig method for jpeg format.
plt.savefig("output_{0}.svg".format('OP')) # savefig method for svg format.
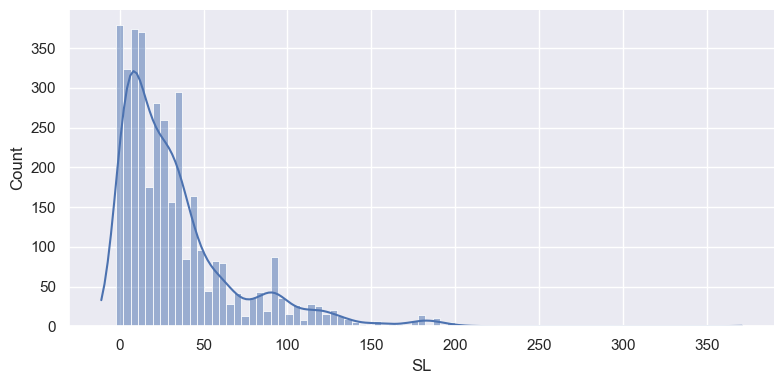
Plotting a categorical variable
- Using the kind=“count” argument on the figure level “catplot” we get a barplot showing the frequency of each value.
- But it needs some work!
sns.catplot(x='Dept', kind="count", data=op_data, height=4, aspect = 2);
pass
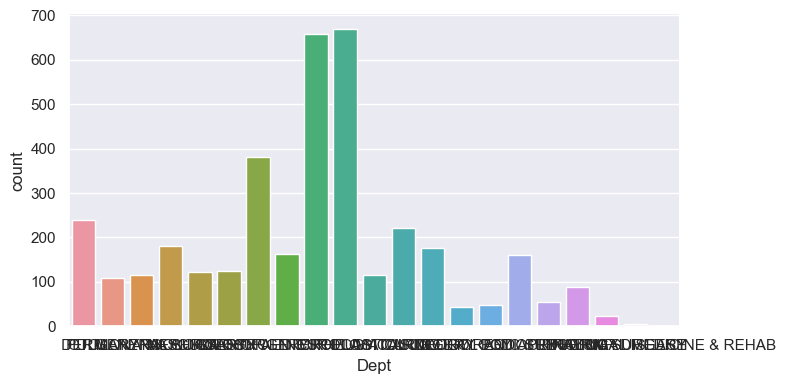
Plot the data
- We can change the size of the catplot directly through the ‘height’ and aspect ‘parameters’.
#### Build the plot
g = sns.catplot(x='Dept', kind="count", palette="ch:.25", data=new_dept, height=3, aspect=2) #ch stands for a "cube-helix" color palette.
g.set_xticklabels(rotation=45, horizontalalignment='right')
plt.subplots_adjust(bottom=0.4) # This adds more white space to the bottom of the plot.
plt.savefig("output_{0}.png".format('Dept')) # savefig method.
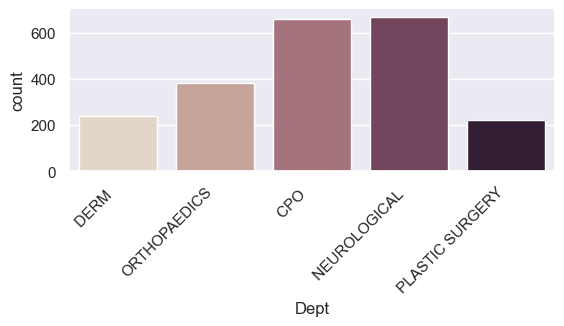
Faceting by the Sex column
new_dept = op_data.loc[op_data['Dept'].isin(top_dept.index)] # Keep all of the columns now.
g = sns.catplot(x='Dept', kind="count", palette="ch:.25", data=new_dept,
col="Sex", height=4, aspect=2) # Note the 'col' argument.
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
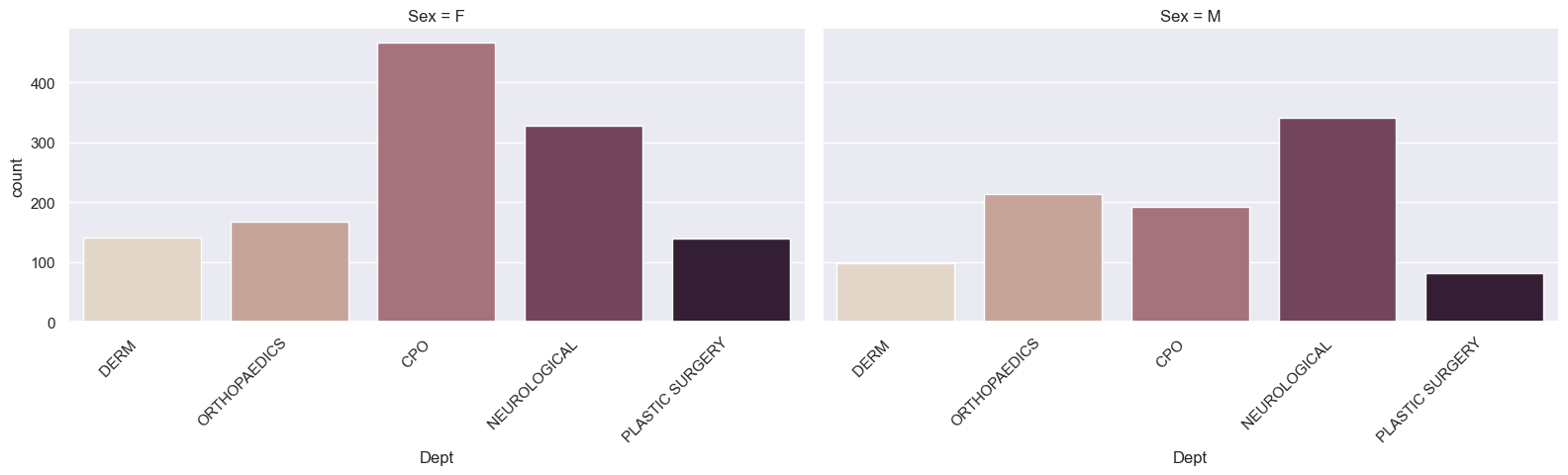
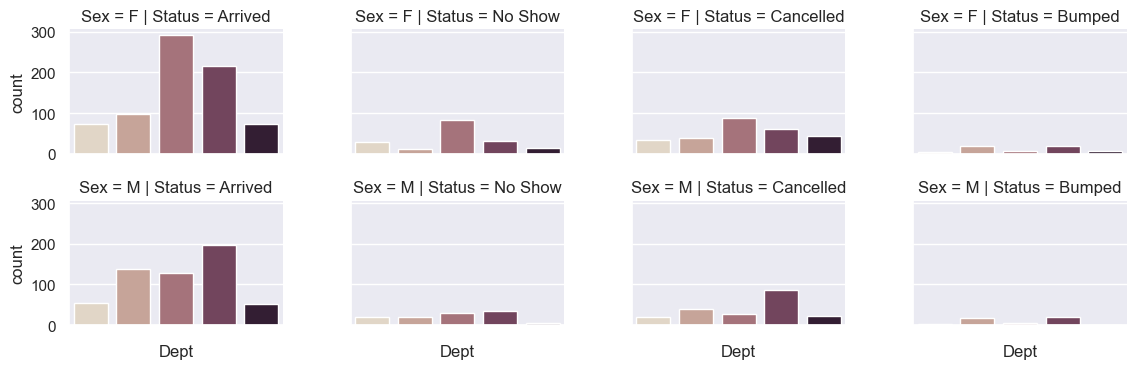
Row and column facets
- Here we condition on Sex (rows) and Status (columns).
g = sns.catplot(x='Dept', kind="count", palette="ch:.25", data=new_dept,
row = 'Sex', col="Status", height=2, aspect=1.5) # Note the 'col' argument.
g.set_xticklabels(rotation=45, horizontalalignment='right')
pass
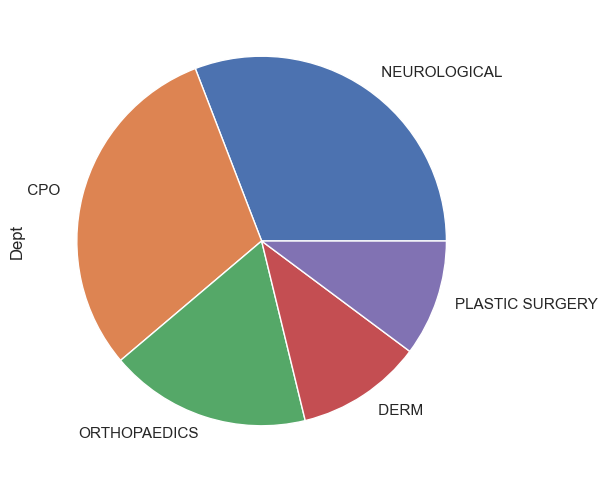
Making a pie chart
- There isn’t a pie chart type in seaborn, but we can use one from pandas.
dept_counts = op_data['Dept'].value_counts()[:5] # Just work with the frequencies here.
dept_counts.plot.pie(figsize=(6, 6)); # This is a pandas plot.
pass
Color in Seaborn
- Seaborn comes with built in color palettes and unless you are artistically talented, it is probably best to stick with them.
- You can view the default palette easily.
current_palette = sns.color_palette()
sns.palplot(current_palette)

sns.palplot(sns.color_palette("Paired")) # The paired palette.

A continuous color palette
- When representing continuous or sequential, rather than categorical data, these may be more appropriate.
sns.palplot(sns.color_palette("Blues"))

Colorbrewer
- There is function called colorbrewer that you can use to help create palettes.
- See color brewer for more information.
custom_palette = sns.color_palette("Reds", 4)
sns.palplot(custom_palette)

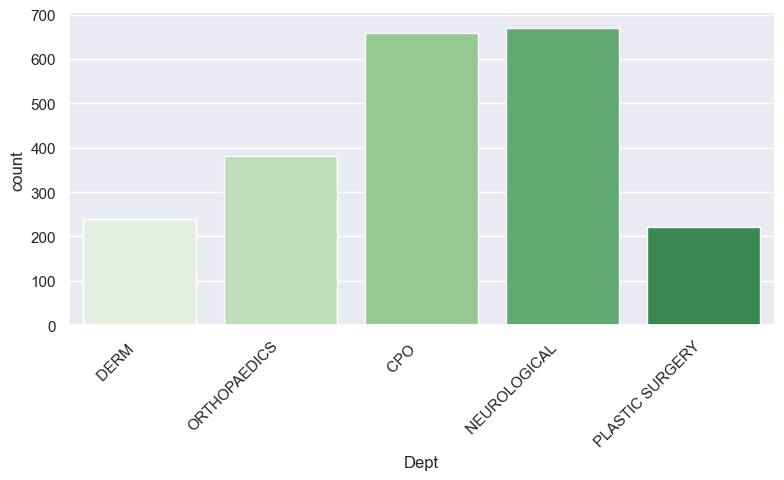
custom_palette = sns.color_palette("Greens", 6)
sns.palplot(custom_palette)

Check out the green graphic
g = sns.catplot(x='Dept', kind="count", palette=custom_palette, data=new_dept, height=4, aspect=2)
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
Cubehelix
- Yet another way of creating sequential palettes is with the “cubehelix” command.
- It takes many potential parameters and below is an example.
sns.palplot(sns.cubehelix_palette(n_colors = 8, start=0.8, rot=.4))

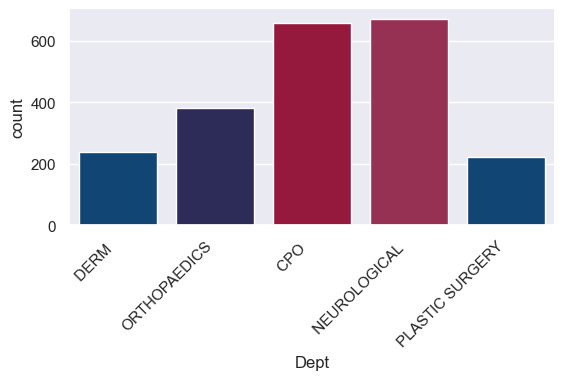
The color dropper in MS Paint
- Note the RGB code for the light blue color in the bottom right of the “Edit Colors” window.

wharton_colors = ["#004785", "#262460", "#A90533", "#A8204E"]
sns.set_palette(sns.color_palette(wharton_colors)) # Set the custom color palette.Build the new graph with custom colors
- We only have 4 colors, but 5 levels to the Department variable, so the colors get “recycled”.
g = sns.catplot(x='Dept', kind="count", palette=wharton_colors, data=new_dept, height=3, aspect=2)
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
Relationships between variables
sns.set_palette(sns.color_palette("flare")) # Use a different palette.
new_dept = op_data.loc[op_data['Dept'].isin(top_dept.index)] #Subset the data.
g = sns.catplot(x = 'Dept', y = "SL", data = new_dept, height=4, aspect=2) # The default "catplot"
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
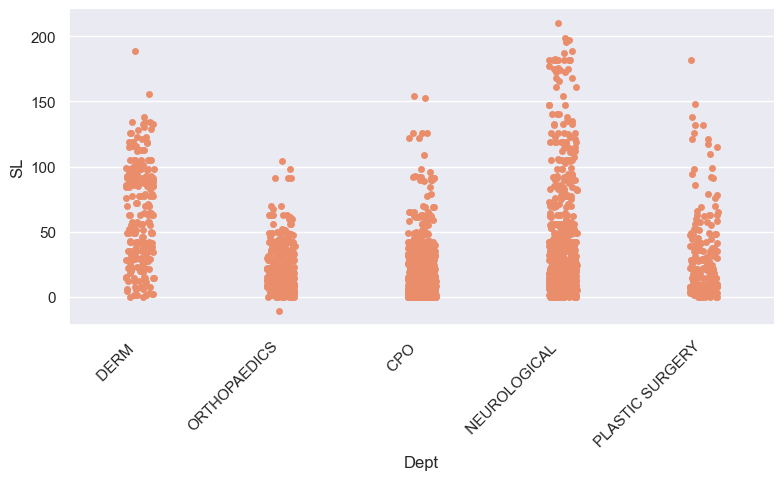
Comparison boxplots
- Here are box plots again, but now with one for each department.
sns.set_palette(sns.color_palette("Set2")) # Use a different palette.
g = sns.catplot(x='Dept',y="SL", kind="box", data=new_dept, height=3, aspect=2) # The comparison boxplots
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
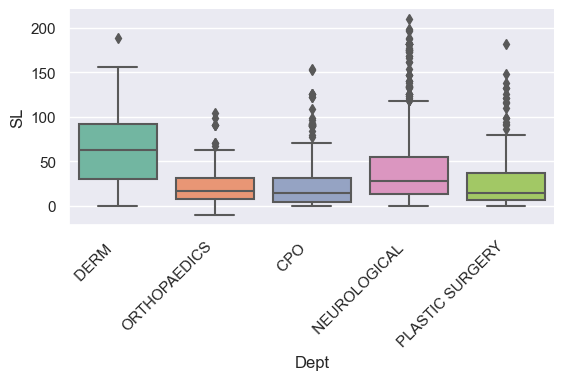
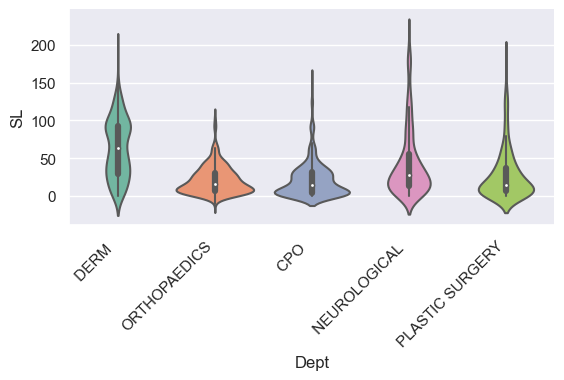
Comparison violin plots
- All we have to do is change the ‘kind’ variable.
g = sns.catplot(x ='Dept', y="SL", kind="violin", data=new_dept, height=3, aspect=2) # The default "catplot"
g.set_xticklabels(rotation=45, horizontalalignment='right');
pass
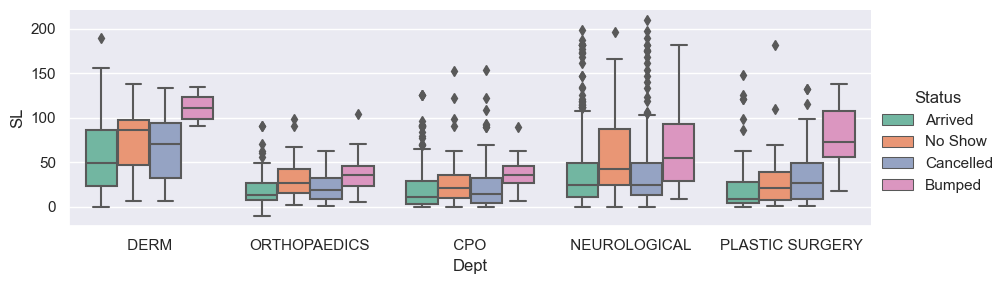
Adding a second categorical variable to the plot
- By using the “hue” argument, we can do the plot over the levels of another variable, to see how consistent the relationship is.
sns.catplot(x = 'Dept', y = "SL", hue ='Status', kind="box", data = new_dept, height=3, aspect=3); # Note the 'hue' argument.
pass
Another way to control the size of the plot
-
If you are using an axes level plot, you can set up the plot size in the following way:
- Use the boxplot command and the axes argument.
f, ax = plt.subplots(1, 1, figsize = (10, 5)) # Set the size of the plot.
sns.boxplot(x = 'Dept', y = "SL", hue = 'Status', data = new_dept, ax=ax); # Note we are back to boxplot.
plt.savefig("output_{0}.png".format('Comps')) # savefig method for png format.
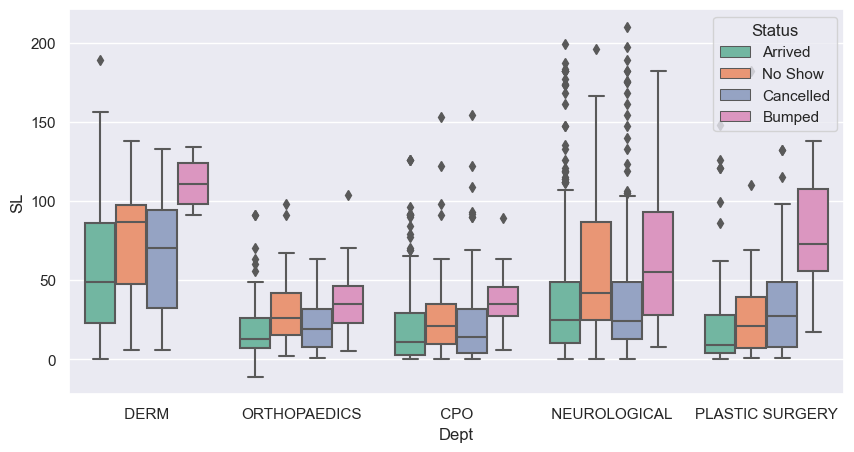
The ‘bar’ type
- Using a bar plot, by default shows the average Schedule Lag, by Status, within each Department.
- The bars (red lines) at the top are confidence intervals for the mean.
g = sns.catplot(x='Dept', y="SL", kind="bar", hue='Status', data=new_dept,
height=4, aspect=3, errcolor="red", errorbar=('ci', 95)) # The 'bar' kind.
g.set_ylabels("Average Schedule lag");
pass
The default plot
This is a simple plot of the two variables.
sns.relplot(x="Weight(lb)", y="GP1000M_City", data=car_data,color="red");
pass
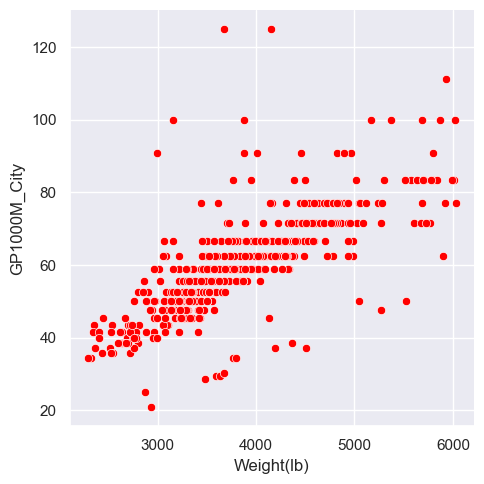
Coloring by a third variable
- The ‘hue’ argument makes the points different colors according to another variable.
sns.relplot(x="Weight(lb)", y="GP1000M_City", hue="Transmission", data=car_data);
pass
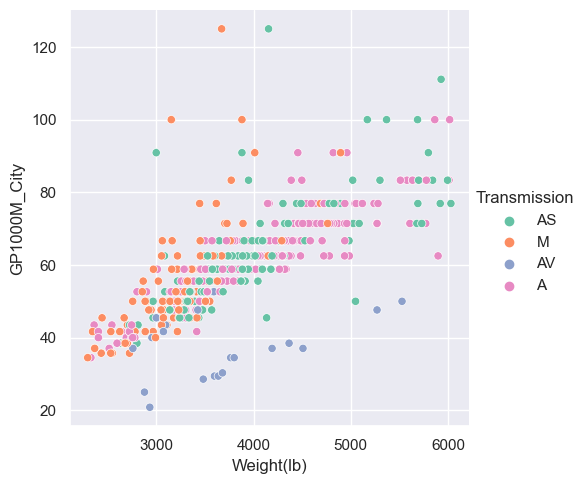
Adding different markers
- The ‘style’ argument changes the plotting character (which may be overkill).
sns.relplot(x="Weight(lb)", y="GP1000M_City", hue = "Transmission", style="Cylinders", data=car_data);
pass
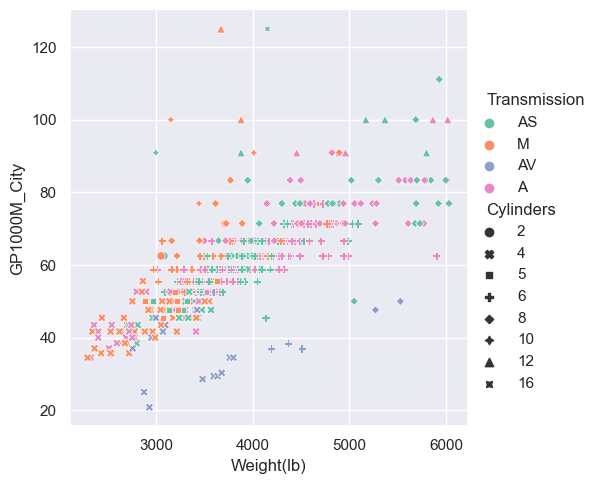
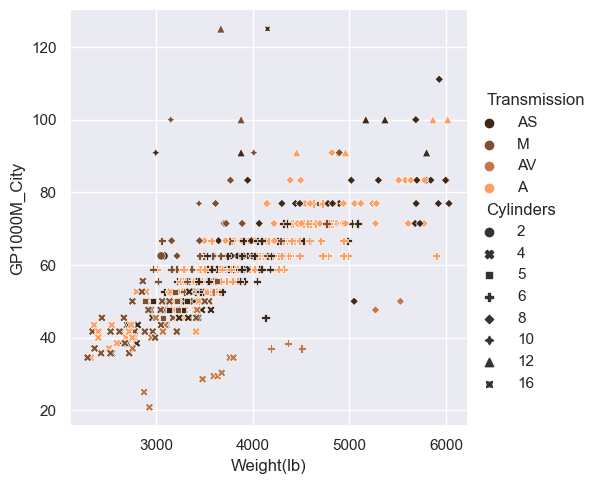
Change the color palette
- As usual, we can add a palette argument.
sns.relplot(x="Weight(lb)", y="GP1000M_City", hue="Transmission", style="Cylinders", palette="copper", data=car_data);
pass
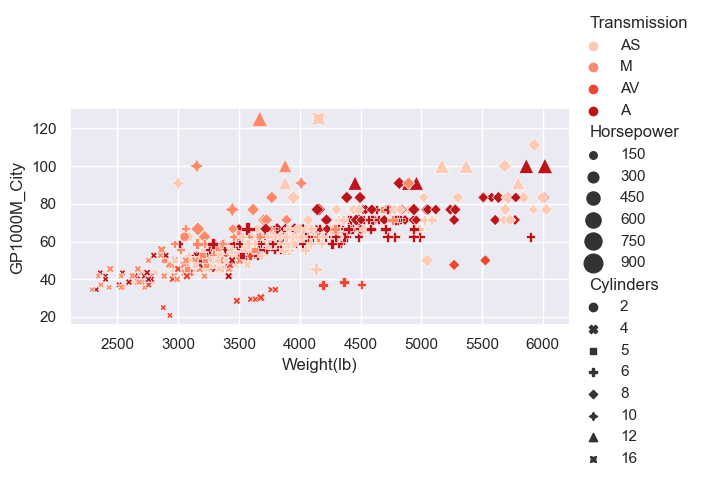
Adding a size based component
- We could potentially use another variable to determine the size of the points, via the ‘size’ argument.
sns.relplot(x="Weight(lb)", y="GP1000M_City", hue = "Transmission", size = "Horsepower",
sizes=(20, 200), style="Cylinders", palette="Reds", data=car_data, height=3, aspect=2);
pass
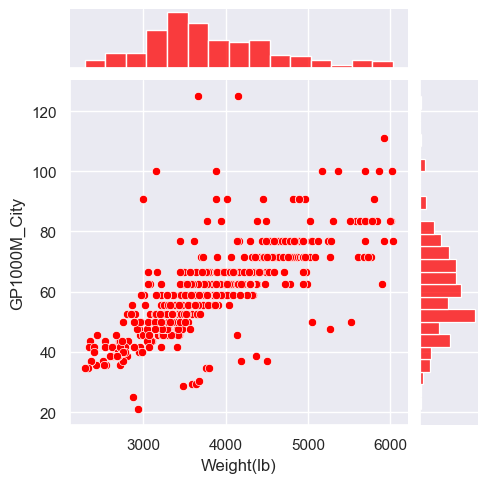
Plotting joint and marginal distributions
- The ‘jointplot’ will also add the univariate distributions on the ‘margins’ (edges) of the scatterplot plot.
sns.jointplot(x="Weight(lb)", y="GP1000M_City", data=car_data, color="red", height=5);
pass
Using a KDE
- We can add one and 2 dimensional KDE’s by using the ‘kind’ equal “kde” option.
sns.jointplot(x="Weight(lb)", y="GP1000M_City", data=car_data, color="red", kind="kde", height=5);
pass
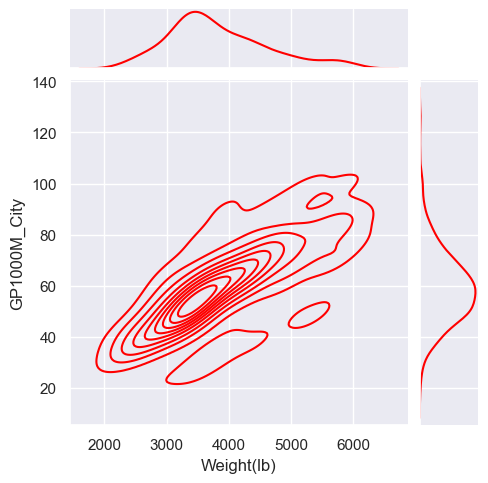
The scatterplot matrix
- A scatterplot matrix shows bivariate relationships and in seaborn uses the ‘pairplot’ command.
sns.set(style="whitegrid", font_scale=0.75) # Change the style
tmp_data = car_data[['GP1000M_City', 'Weight(lb)', 'Horsepower', 'Length', 'Transmission']]
sns.pairplot(tmp_data, hue="Transmission", height=2);
plt.savefig("output_{0}.png".format('Cars')) # savefig method for png format

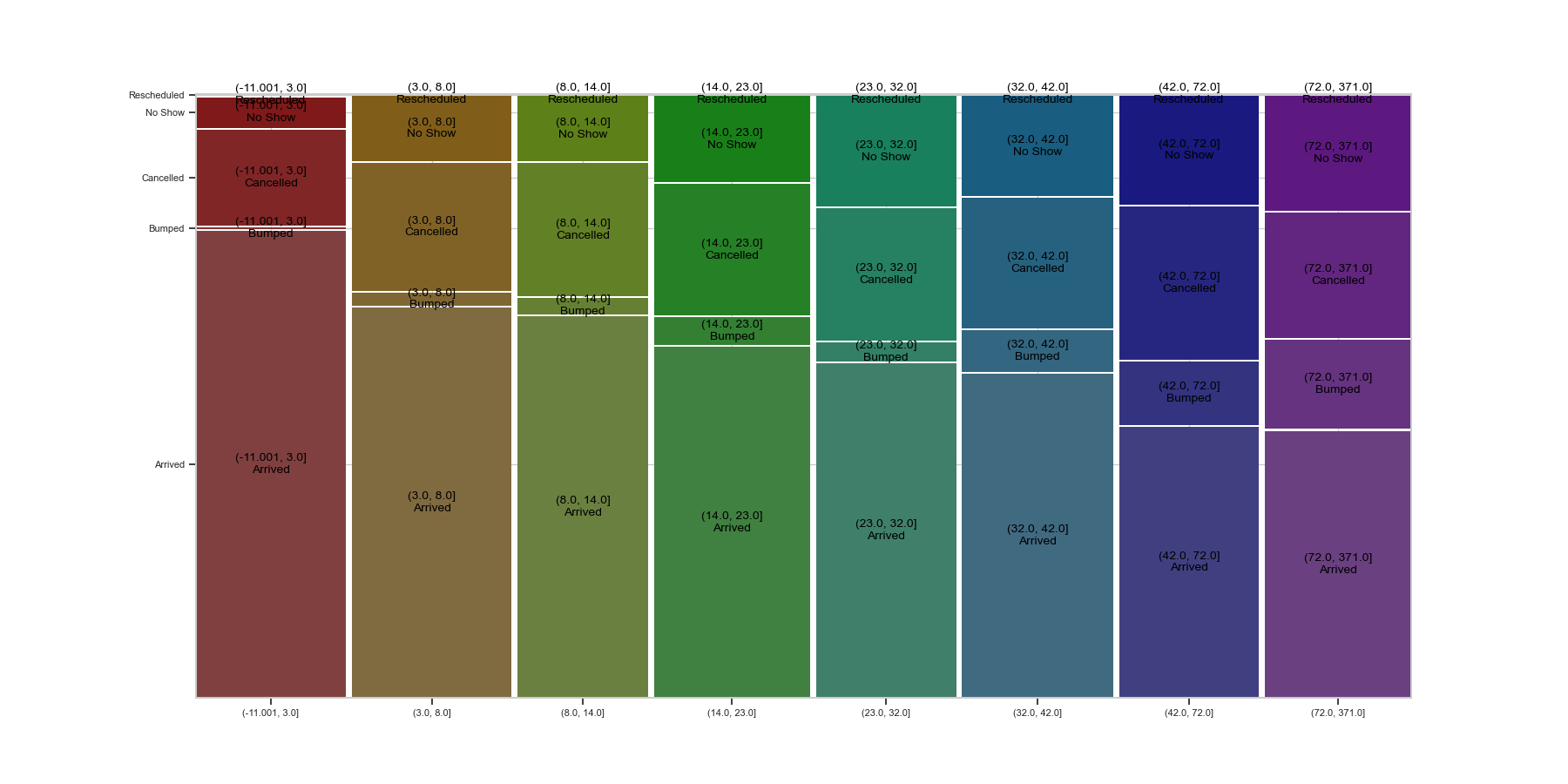
Plotting two categorical variables
- The usual plot for two categorical variables is called a “Mosaic plot” and plots the proportion in each level of a y-variable, over the levels of an x-variable.
- Seaborn doesn’t have this plot, but we can find one in the statsmodels package.
from statsmodels.graphics.mosaicplot import mosaic
mosaic(op_data, ['Sex', 'Status']);
pass
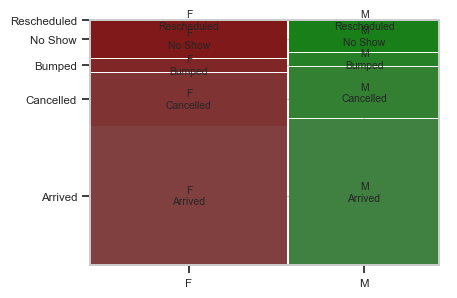
The finished mosaic plot